Artificial intelligence has firmly entered the modern workplace. From automated email replies to document summaries, classification tasks, research, and personalized messaging — AI now handles tasks that were once manually performed.

Companies adopt these tools because they save time, simplify processes, and reduce routine work.
But as AI becomes more deeply embedded in business communication, one question becomes unavoidable:
How can organizations use AI without exposing sensitive data or introducing new privacy risks?
The answer lies in a principle deeply rooted in the GDPR — and often misunderstood:
Data Minimization.
A simple, powerful concept that forms the foundation of trustworthy AI systems — yet is neglected by many vendors.
This article explains:
- what data minimization truly means (GDPR Art. 5),
- why many AI tools violate it without users noticing,
- the risks companies unknowingly take,
- and why “processing without storing” is becoming the new gold standard for AI.
No scaremongering, no product advertising — just clarity, substance, and guidance.
1. What Data Minimization Actually Means According to GDPR Article 5
Many associate the GDPR with bureaucracy and paperwork.

But its core is surprisingly simple:
Process only the data you truly need — and as little of it as possible.
Article 5(1)(c) states:
Personal data must be adequate, relevant and limited to what is necessary for the purposes for which they are processed.
In practice, this means:
- Don’t collect more data than needed
- Don’t store data longer than necessary
- Don’t create “just in case” data pools
- Reduce processing to the absolute minimum
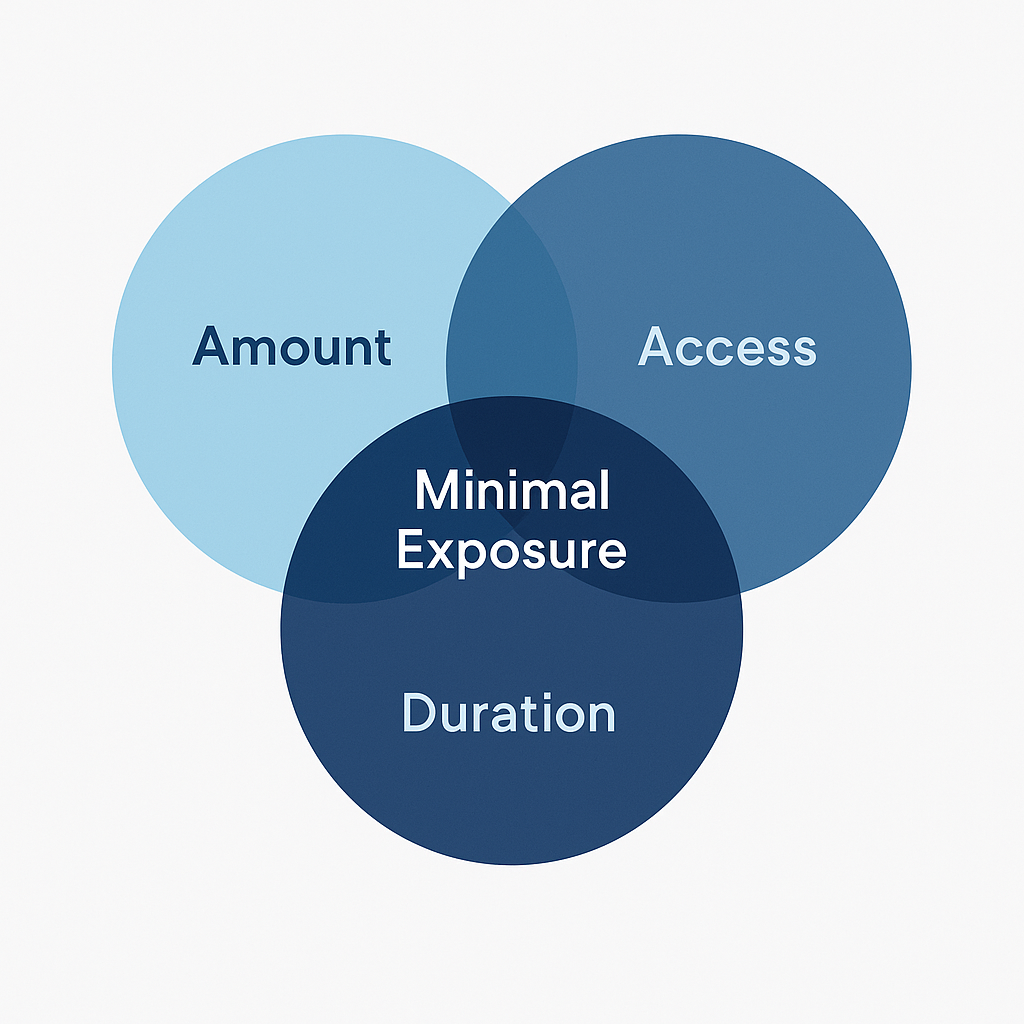
Data minimization has three dimensions:
1. Minimization of Amount
Only process the data strictly required for the task.
2. Minimization of Access
Only the systems and individuals who truly need access should have it.
3. Minimization of Duration
Data should not be stored permanently.
Temporary processing is the ideal state.
This principle aligns perfectly with modern AI architectures:
- short-lived data
- stateless processing
- API-based execution
- no persistent storage
Yet reality looks very different.
2. Why Most AI Tools Ignore Data Minimization
Behind the scenes of many popular AI email assistants and productivity tools lies a clear pattern:
Most of them store entire mailboxes, communication histories, metadata, and user information on their servers.
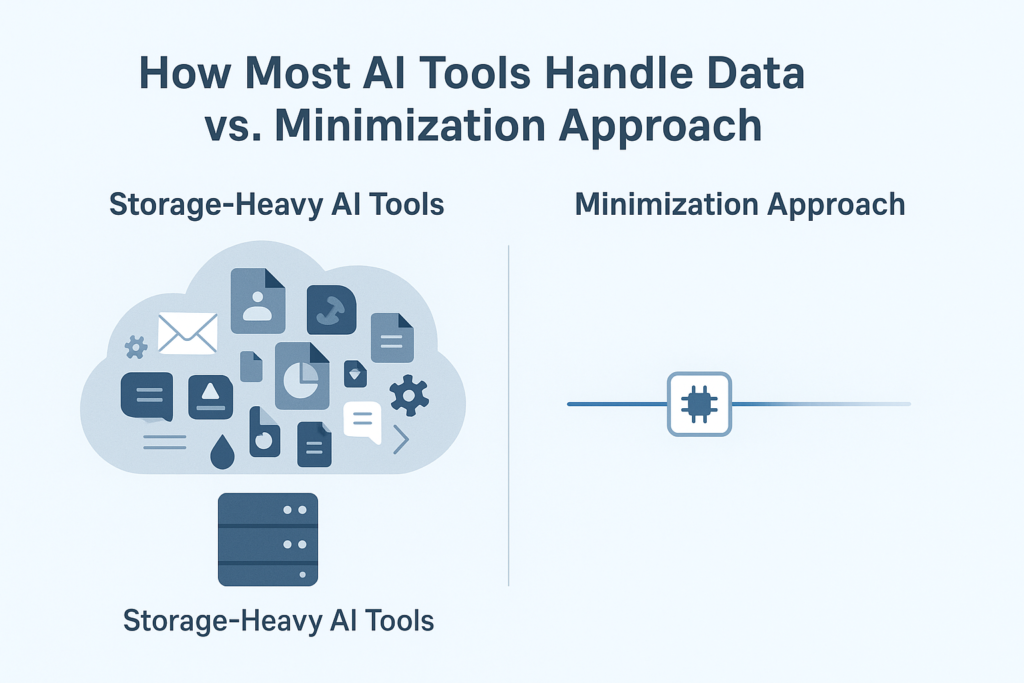
Why?
Because it’s easier for vendors.
Mailbox storage enables smart search
Conversation history improves personalization
Historical data helps refine models internally
Full copies support analytics and dashboards
Convenient for vendors — risky for companies.
Why many AI tools violate GDPR principles

1. Feature-driven product thinking
“Wouldn’t it be useful to store everything — you never know?”
A common internal mindset.
2. Business models built on data retention
Some vendors aim to analyze or monetize data later.
3. Technical convenience
Storing data makes systems simple.
Ephemeral processing requires thoughtful engineering.
4. U.S.-centric software culture
Many tools are built in jurisdictions with weaker baseline privacy laws.
Unlike the GDPR, the U.S. has no federal privacy law, only sectoral laws:
- CCPA/CPRA (California — closest to GDPR concepts)
- Virginia CDPA
- Colorado CPA
- Connecticut CTDPA
- Utah UCPA
- HIPAA (health data)
- GLBA (financial institutions)
- FERPA (education data)
5. Misinterpretation of GDPR
Some assume GDPR only applies to large databases.
Wrong — a single stored email containing a name is personal data.
3. How Companies Unknowingly Expose Themselves to Risk
When organizations use AI tools that store mailboxes on servers, they often fail to understand the consequences.
Below are the key risks — real and concrete.
Risk 1: New Attack Surfaces from Storing Complete Mailboxes
Every additional data pool is:
- a potential attack vector
- a risk for data breaches
- a compliance complication
- a documentation burden
AI tools that replicate entire inboxes double or triple the attack surface.
In the U.S., this is even riskier due to:
- eDiscovery exposure
- subpoena risk
- Third-Party Doctrine (government access to data stored with vendors)
Risk 2: Loss of Control Over the Data Lifecycle
When data is stored on third-party servers:
- Who truly deletes it?
- What happens after contract termination?
- How long do backups remain?
- Which employees have access?
Many vendors remain vague — especially U.S. providers governed by broad subpoena powers.
Risk 3: Increased Legal Obligations
Once data is stored, organizations must handle:
- Data Processing Agreements
- deletion obligations
- documentation duties
- TOMs (technical & organizational measures)
- Data Protection Impact Assessments (DPIA)
In the U.S., equivalents include:
- HIPAA BAAs
- GLBA Safeguards Rule
- CPRA service-provider contracts
- FTC Act Section 5 enforcement
Most SMEs are unprepared for this.
Risk 4: Reputation Damage
Even small incidents can cause:
- loss of trust
- negative media coverage
- customer churn
- legal disputes
Trust is a competitive advantage — especially in consulting, finance, and healthcare.
Risk 5: Vendor Lock-in
If a vendor stores the entire mailbox:
- switching becomes difficult
- data exportability is unclear
- deletion transparency decreases
A long-term dependency is created.
4. Why “Processing Without Storing” Is Becoming the New AI Standard
AI does not need to store data to function effectively.
Modern systems rely on:
- stateless APIs
- short-lived processing
- event-based architecture
- draft creation without retention
- temporary context processing
This architecture brings massive benefits.
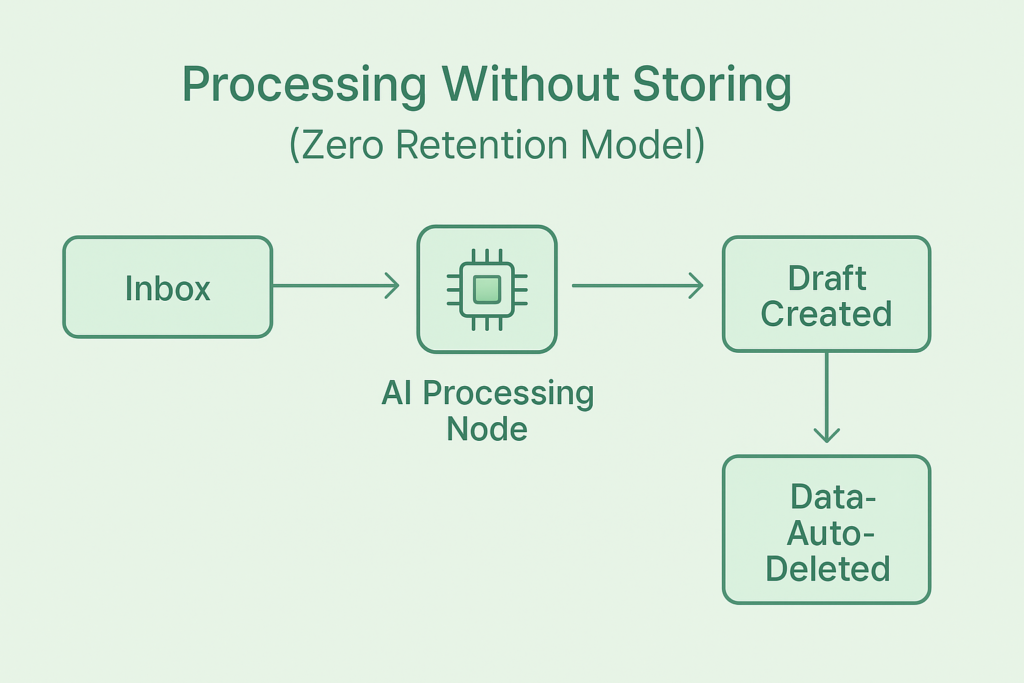
1. Security Through Non-Existence
What isn’t stored cannot be stolen.
2. GDPR Compliance by Design
Data minimization becomes part of the architecture, not an afterthought.
3. Less Organizational Overhead
No deletion plans, no retention policies, no extra documentation.
4. No Vendor Lock-in
If nothing is stored, switching vendors is trivial.
5. Higher Trust
Users trust tools that demonstrably do not retain data.
In U.S. terms, ephemeral AI aligns with:
- CCPA/CPRA Data Minimization Requirements
- NIST Privacy Framework “Data Processing Minimization”
- HIPAA “Minimum Necessary Standard”
- FTC’s unfairness doctrine (minimizing unnecessary retention)
5. Outlook: Companies Demand AI With Minimal Data Footprint

As AI becomes more widespread, decision-makers increasingly scrutinize:
- data flows
- storage locations
- access rights
- deletion capabilities
- architectural design
- compliance risks
The trend is unmistakable:
AI systems that do not store data will dominate the European market — and increasingly the U.S. market as well.
Particularly in:
- consulting
- tax advisory
- law firms
- HR
- healthcare
- finance
- SMEs across industries
These sectors need clarity and certainty.
6. Why Many Vendors Must Rethink Their Architecture
Tools built on persistent storage face major challenges:
- eliminating server-side mailbox copies
- redesigning models and workflows
- implementing zero-retention
- rethinking privacy by design
- enabling stateless processing
- building EU-ready and CCPA-ready architectures
It’s difficult — but unavoidable.
7. Data Minimization Is Not a Limitation — It’s a Competitive Advantage
Often, privacy is seen as a blocker of innovation.
In truth, the opposite is happening:
Less data leads to:
- clearer systems
- lower risks
- higher trust
- better scalability
It forces vendors to build smarter, safer solutions.
Conclusion: Data Minimization Is the Future of Responsible AI

AI evolves quickly — but trust evolves slowly.
Companies want modern AI without introducing new risks.
The GDPR provides a clear principle:
As much as necessary, as little as possible.
Many AI tools ignore this principle because it is inconvenient.
But the market is shifting.
AI solutions that do not store data offer exactly what companies need today:
- security
- simplicity
- trust
- future viability
Data minimization is not merely a regulatory idea —
it is a technological advancement and a hallmark of responsible AI.