From Fear to Opportunity
In many public discussions, the General Data Protection Regulation (GDPR) is portrayed as a barrier to innovation. The underlying assumption is that strict rules, purpose limitation, and information obligations slow down creative technological development. But this view ignores that legal frameworks can also be engines of innovation.
GDPR is built on principles such as lawfulness, purpose limitation, data minimization, and transparency. These principles force developers and companies to structure their systems cleanly, process only the necessary information, and respect data subjects’ rights. Precisely because GDPR defines this framework so clearly, it creates trust among customers, employees, and partners. That trust is the essential foundation for accepting new technologies — and therefore for innovation.
U.S. equivalents reinforce the same dynamic. The California Consumer Privacy Act (CCPA) and California Privacy Rights Act (CPRA) emphasize transparency, purpose limitation, and “reasonably necessary and proportionate” data use. Sector-specific laws like HIPAA (healthcare), GLBA (financial institutions), and FERPA (education) encourage disciplined data governance. The FTC Act Section 5 prohibits “unfair or deceptive practices,” which includes misleading data handling claims. Together, these laws push organizations toward responsible AI design — much like GDPR.
Many European regulators emphasize that GDPR is not intended to block AI development. France’s CNIL explicitly states that GDPR enables “innovative and responsible AI” by providing legal certainty. A scientific study by the Humboldt Institute for Internet and Society shows that GDPR’s purpose-limitation principle creates strategic space for innovative companies, helping them control risk and ultimately gaining competitive advantages.
GDPR, therefore, is not an obstacle — but a blueprint for trustworthy technologies.

Data Protection as a Driver of Technical Excellence
GDPR’s principles force clear architectural decisions. Data minimization requires processing only the amount of personal data truly necessary — a concept mirrored in the NIST Privacy Framework, which prioritizes necessity, proportionality, and data lifecycle controls.
CNIL highlights that data minimization does not prohibit the use of large training datasets; rather, it motivates developers to curate and refine them carefully. This reduces unnecessary storage, lowers breach risk, and helps models learn more effectively.
Purpose limitation also creates design freedom. According to the HIIG study, this principle gives companies enough flexibility to align innovation processes with legal obligations. The ability to work with supervisory authorities to create practical implementations increases legal certainty and strengthens trust in new products. Early clarification of data purposes saves expensive redesign later — this matches best practices recommended under the U.S. AI Risk Management Framework (NIST RMF).
Combined with “Privacy by Design and by Default,” a positive feedback loop emerges. The original Privacy-by-Design framework by Ann Cavoukian — also influential in U.S. regulatory thinking — emphasizes that privacy and innovation are not zero-sum but positive-sum: full functionality and strong data protection.
Companies adopting this mindset integrate privacy into their business models, gaining a durable competitive advantage.
Ephemeral Processing and Zero Retention: Process, but Never Store
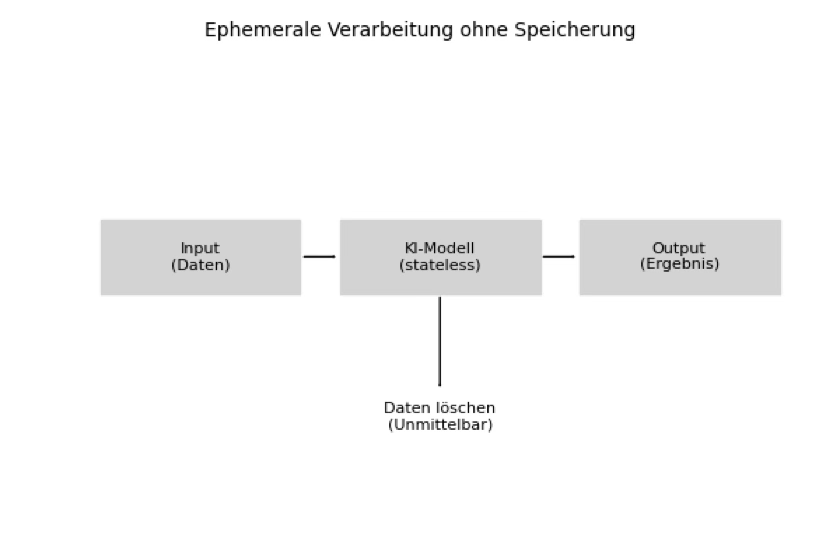
A direct consequence of data minimization is the shift toward ephemeral data flows. Data is processed only for as long as needed and then immediately deleted. Modern AI architectures can process requests entirely in volatile memory (RAM), ensuring neither inputs nor outputs ever reach persistent storage.
This aligns with GDPR and also reduces exposure under U.S. legal doctrines. For example:
- Under the Third-Party Doctrine, authorities may compel cloud providers to hand over stored data — but ephemeral processing leaves nothing to obtain.
- Under CCPA/CPRA, companies must honor the right to delete and justify retention — zero retention solves this elegantly.
- For HIPAA-regulated entities, storing fewer copies reduces breach liability and Business Associate Agreement (BAA) exposure.
Zero-retention systems process incoming information locally or through temporary compute environments. Only mission-critical information is extracted; the rest is discarded immediately. This makes systems easier to audit, reduces compliance burden, and strengthens user trust.
CNIL explicitly recommends building privacy into models from the beginning and anonymizing data where possible. New research areas such as stateless AI and ephemeral AI highlight that models without persistent storage are legally simpler, because no data exists for potential disclosure.
In practice, this means: Instead of mirroring email inboxes to external servers, a zero-retention system processes messages locally or inside ephemeral compute instances. Only what is necessary is used; everything else is deleted instantly.
The result: cleaner audits, lower risk, higher trust.
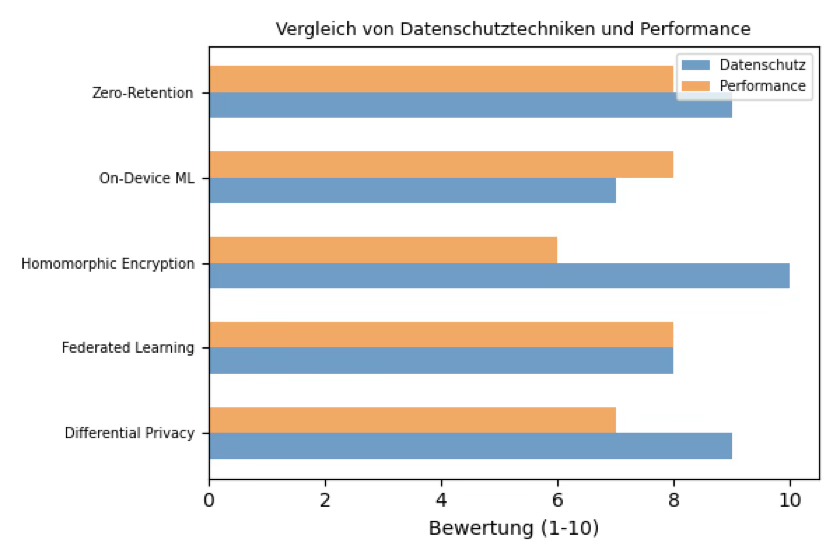
Innovation Despite Strict Rules: Privacy-Enhancing Technologies (PETs)
Strict privacy regulations have not stifled innovation — they have produced an entire class of Privacy-Enhancing Technologies (PETs). These methods integrate mathematical and technical protections directly into workflows.
Differential Privacy
Introduces statistical noise to prevent re-identification. Used extensively by Apple, Google, and the U.S. Census Bureau.
Federated Learning
Models are sent to user devices; only aggregated updates return. This keeps raw data on the device and aligns with both GDPR and HIPAA/FERPA constraints.
Homomorphic Encryption
Allows computations on encrypted data without ever exposing plaintext.
On-Device Machine Learning & Secure Enclaves
Local processing avoids cloud transfer altogether; secure enclaves protect model and data integrity.
Zero-Retention Architectures
Guarantee that no personal data is stored beyond the request cycle.
Reports by the Center for Democracy and Technology (CDT) and Cisco show that companies embracing privacy as part of innovation become more competitive and gain consumer trust. CCPA enforcement in the U.S. has shown similar results: privacy investments pay off.
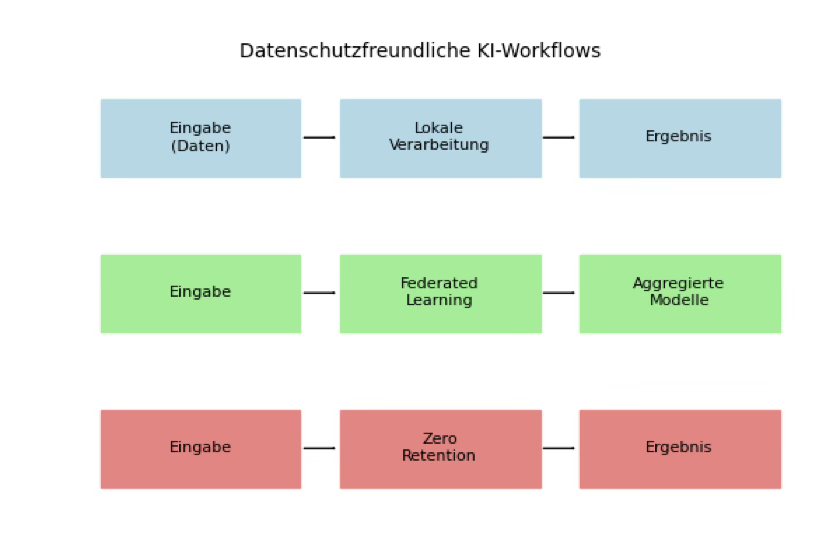
Privacy-Friendly AI Workflows: Practical Examples
How can AI systems be designed to meet GDPR requirements — and U.S. privacy expectations — while remaining powerful? Three patterns dominate:
1. Local Processing
Sensitive data never leaves the device. This reduces GDPR obligations, eliminates CCPA deletion liabilities, and avoids subpoena exposure under U.S. cloud law.
2. Federated Learning
The model trains on-device; only gradients are shared. Useful for healthcare (HIPAA), finance (GLBA), and education (FERPA).
3. Zero-Retention & Ephemeral Services
Requests are processed in memory and then immediately wiped. No logs with personal data persist. This supports GDPR principles, CCPA deletion rights, and NIST data minimization strategies.
These architectures demonstrate that strong privacy does not reduce performance — it encourages cleaner, more efficient, more resilient system design.
Companies implementing these workflows often develop new business models: premium local processing, decentralized AI ecosystems, and privacy-first services for sensitive industries.
Trust as a Competitive Advantage and Innovation Engine
Privacy-compliant products enjoy higher trust — crucial in a world of increasing data scandals and AI fears. CDT notes that strong privacy laws create fair competition and protect consumers. Similarly, the CPRA introduced the California Privacy Protection Agency (CPPA), increasing oversight and motivating higher standards — similar to GDPR’s supervisory authorities.
Many companies used GDPR as an opportunity to clean internal systems — comparable to the “data inventory refresh” triggered by CCPA in the U.S. The result: streamlined processes, lower security risks, and more satisfied customers.
GDPR also enables cooperation with regulators through co-regulation. Companies can work with authorities to design tailored solutions, certification schemes, and codes of conduct — similar to voluntary compliance frameworks promoted by NIST.
Over time, privacy-first architectures become the norm, not the exception.
Conclusion: GDPR as a Blueprint for Responsible AI
GDPR is not an innovation blocker — it is an opportunity. It defines clear rules for personal data processing while leaving room for technical creativity. Approaches such as ephemeral processing, zero retention, federated learning, homomorphic encryption, and differential privacy prove that privacy and performance complement each other.
Companies that embrace GDPR principles gain trust, reduce liability, and build strong, efficient architectures. By designing privacy-friendly AI systems today, organizations position themselves as leaders of tomorrow’s responsible and successful technology landscape.